
Einleitung und Zielsetzung
Mittlerweile hat die künstliche Intelligenz (KI) auch Einzug in den Bereich des Softwaretestens erhalten. Insbesondere im Bereich des UI-Testens (Erkennen von Oberflächen) finden sich hier viele Lösungen. Diese Lösungen setzen also ein entsprechend entwickelte Benutzeroberfläche voraus.
In diesem Ansatz verfolgen wir aber ein anderes Ziel: Die KI soll schon frühzeitig im Entwicklungsprozess den Test und somit auch die Entwicklung unterstützen. Wir gehen davon aus, dass in natürlicher Sprache Testfälle erfasst wurden. Mittels Natural Language Processing (NLP) sollen diese in Skripte für einen Testroboter transformiert werden.
Zielvision ist, dass aus von Fachanwender:innen formulierte Tests für bestimmte Anforderungen (User Stories) mittels des hier vorgestellten Verfahrens in ausführbare Testskripte umgesetzt werden und somit das Testen enorm beschleunigt werden kann. Das würde insbesondere das Test Driven Development (TDD) unterstützen, aber der Nutzen ist unabhängig von der Methodik.
Grundlagen Testwerkzeuge und NLP
Testwerkzeuge
Benötigt werden hauptsächlich zwei Arten von Testwerkzeugen:
Testroboter: mateo
In diesem Szenario nutzen wir konkret die Testautomatisierungssoftware mateo. mateo ist ein Testroboter, der in einer entsprechenden Sprache geskriptete Testfälle oder Prozessbeschreibungen durchführt und auswertet. mateo-Kommandos bestehen aus Befehlen und Parametern, die in der mateo-Dokumentation und der Weboberfläche verfügbar sind.
Testmanagement: XRAY
Xray ist ein Softwaretestmanagementwerkzeug für Jira, das Jira um fünf neue Vorgangstypen erweitert: Test, Testset, Testausführung, Testplan und Vorbedingung. Ein Test (Typ=manuell) in Xray besteht aus Testschritten, Bedingungen, Testeingabedaten und erwarteten Ergebnissen. Xray bietet viele Vorteile für das Testmanagement, eine davon ist die einfache Importmöglichkeit von Tests über die REST API.
NLP
Grundsätzlich teilt sich NLP (Natural Language Processing) auf in das Verstehen natürlicher Sprache (Natural Language Understanding, NLU), um Bedeutung aus Texten zu extrahieren, und in die Erzeugung natürlicher Sprache (Natural Language Generation, NLG), um Texte aus Computerdaten zu generieren. Aber mit der Zeit hat sich NLP von einfachen regelbasierten Ansätzen zu neuronalen Sprachmodellen entwickelt, die die Wahrscheinlichkeit von Wortfolgen basierend auf dem Kontext analysieren. Diese Modelle lernen Sprachstrukturen, interne Logik und Kontextverständnis. Die modernen NLP-Modelle nutzen tiefe neuronale Netze mit Transformer-Architekturen für leistungsfähigere und effizientere Anwendungen. In der Entwicklung der Modelltrainingsmethoden hat sich die Praxis des Vortrainings großer Sprachmodelle als besonders beliebt erwiesen. Beim Transferlernen wird das Modell zuerst für eine allgemeine Aufgabe geschult und dann gezielt für spezifische Aufgaben angepasst.
In dieser Arbeit wurde ein ähnliches Modell verwendet: das GPT-3.5-turbo-Modell von OpenAI in Kombination mit der Few-Shot-Learning-Methode, das auf der Transformer-Architektur basiert. Das Modell hat ein zweistufiges Transferlernsystem, bei dem das Modell zunächst mit natürlichsprachigen Texten geschult wurde, um Sprachverständnis zu entwickeln. Dieses Training wurde vom OpenAI-Team durchgeführt. In der zweiten Stufe wurde das Modell mithilfe des Few-Shot-Lernens an die spezifische Zielaufgabe angepasst, indem Aufgabenbeschreibungen und Beispiele verwendet wurden. Dieses Training passiert im Rahmen dieser Forschung. Bei Few-Shot kann die Aufgabe auch etwas anders beschrieben werden, nämlich als Beginn des Kontextes des letzten Beispiels. Vom Modell wird dann erwartet, dass es die Vervollständigung dieses Beispiels liefert.
Prototyp – Prämissen, Erstellung und Ergebnisse
Prämissen
Die Idee des Prototyps findet Anwendung im Testalltag und bietet sowohl erfahrenen Tester:innen als auch Personen ohne Programmierkenntnisse einen Nutzen. Erfahrene mateo-Nutzer:innen können bei der Skripterstellung Zeit sparen, während der Prototyp für Einsteiger:innen in die Testautomatisierung einen einfachen Einstieg bietet. Darüber hinaus zeigt der Prototyp das Potenzial künstlicher Intelligenz in der mateo-Automatisierung auf.
Zur Nutzung des Prototyps müssen als Lernbasis sowohl Testfälle aus Xray als auch entsprechende mateo-Skripte bereitgestellt werden. Für die Entwicklung eines neuen Testskripts muss dann noch ein Testfall aus Xray übergeben werden.
Erstellung
Der funktionale Kern eines Testskripts ist der umgangssprachlich beschriebene Testfall selbst. Die ersten oder vorbereitenden Schritte bei der Prototypenerstellung beinhalten die sorgfältige Dokumentation der Testfälle (Testschritte und Sollergebnisse). Alle Testdokumentationen werden in Jira mithilfe von Xray erfasst, was ein einheitliches Format für sämtliche Tests gewährleistet. Dieses Vorgehen erleichtert die Entwicklung einer einzelnen Codefunktion zur Datenextraktion.
Insgesamt wurden sechs Testfälle in Xray ausführlich dokumentiert, wobei die Testschritte besonders detailliert festgehalten wurden. In jedem Testschritt sind eine Aktion, benötigte Daten und das erwartete Ergebnis notiert. Es ist ebenso wichtig zu beachten, dass die Daten, die bei der Ausführung des Testfalls genutzt werden sollen, in einem speziellen Format vorliegen.
Weiterhin es ist wichtig, die mateo-Testskripte zu den in Xray dokumentierten Testfällen zu erstellen. Für bestmögliche Ergebnisse empfiehlt sich hier auch eine zumindest einheitliche Art der Codierung. Clean-Code-Ansätze sind grundsätzlich auch in der Entwicklung von Testskripten eine gute Empfehlung und fördern hier natürlich insbesondere die Qualität der Ergebnisse. Die erstellten mateo-Testskripte werden anschließend für das Training verwendet. Sobald diese Daten vollständig vorliegen, kann mit Prototyp-Skript begonnen werden.
Die Erstellung neuer Testskripte erfolgt in zwei aufeinanderfolgenden Schritten. Im ersten Schritt werden die Daten aus Xray sowie die Informationen aus den geschriebenen mateo-Testskripten in ein für das Modell geeignetes Format umgewandelt. Anschließend folgt der zweite Schritt, bei dem die Zieltests mithilfe eines Sprachmodells in ein Testskript transformiert werden. Dabei erfolgt die Interaktion mit dem Modell über die OpenAI-Schnittstelle (API). Es ist jedoch wichtig zu beachten, dass die API dazu verwendet wird, auf die OpenAI-API zuzugreifen, und nicht für den direkten Zugriff auf das Modell selbst.
Das Endergebnis hängt entscheidend von den verwendeten Trainingsdaten ab. Daher wurden verschiedene Arten von Trainingsdaten und entsprechende Trainingsmethoden betrachtet. Bei der ersten Methode dienen einzelne Testschritte und die dazugehörigen mateo-Testschritte als Beispiele für das Training. Bei der zweiten Methode wird ein vollständiges Testskript sowohl in natürlicher Sprache als auch im mateo-Format verwendet. Um die Wirksamkeit der beiden Trainingsansätze zu bewerten, wurde ein Testskript unter Verwendung beider Methoden erstellt. Insgesamt wurden sechs Tests für die Entwicklung, fünf für das Training und einer zur Überprüfung der Effektivität der Trainingsdaten verwendet.
Nachdem die Testskripte mit beiden Varianten erstellt wurden, erfolgte eine umfassende Analyse der resultierenden Skripte hinsichtlich ihrer Struktur, ihres Inhalts und ihrer Funktionalität. Zusätzlich wurde der Inhalt der Skripte in Schritte unterteilt, um detaillierte Ergebnisse zu erhalten. Es ist erwähnenswert, dass der Inhalt der generierten Testskripte mit dem vom Tester erstellten Muster für denselben Testfall verglichen wird, um die Qualität zu überprüfen. Diese Ergebnisse sind in einer Tabelle zusammengefasst, die die verschiedenen Parameter für Trainingsdaten und Vergleiche zeigt. Häkchen und Kreuze zeigen den Erfolg oder Misserfolg jedes Parameters an.
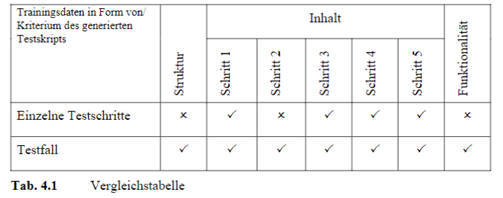
Die Tabelle zeigt, dass insgesamt beide Varianten der Trainingsdaten recht gut abschneiden. Die Hauptfunktion der Testskripte liegt aber in der Funktionalität, nämlich der Durchführung automatisierter Tests. Ein nicht funktionierendes Skript ist daher wertlos, wie es zum Beispiel bei der ersten Variante der Fall ist. Im Gegensatz dazu erzielt die zweite Variante hervorragende Ergebnisse, was sie zur bevorzugten Wahl für den Prototyp macht.
Fazit und Ausblick
Der entwickelte Prototyp, der Testschritte aus der Testmanagementanwendung Xray extrahiert und in ein Testskript für die Testautomatisierungsanwendung mateo konvertiert, hat sich als erfolgreich erwiesen. Insbesondere die Leistung des Teils, der das Testskript selbst generiert, erfüllt die Erwartungen. Dies zeigt, dass Natural Language Processing (NLP) im Allgemeinen verwendet werden kann, um eine natürlichsprachliche Testfallbeschreibung, die in Form von Testschritten in einer Testmanagementanwendung vorliegt, in ein Testskript umzuwandeln.
Im weiteren Verlauf soll dieser Prototyp nun mit einem echten Projekt und dessen Tests evaluiert werden. Dabei wollen wir untersuchen, inwieweit die Erfahrungen in der „rauen Alltagsrealität” Ergebnisse liefern, die mit den Laborergebnissen vergleichbar sind (d.h. funktionierende Testskripte, die auch das Testen was in der natürlichsprachlichen Testfallbeschreibung erfasst ist) oder wo für eine produktive Nutzung noch Anpassungen erforderlich sind.
Die Autor:innen
 Jörg Irle ist Seniorberater und seit 1997 für die viadee IT-Unternehmensberatung tätig. Seine Schwerpunkte liegen besonders in den Bereichen Business Analyse, Projektmanagement und Qualitätssicherung.
Jörg Irle ist Seniorberater und seit 1997 für die viadee IT-Unternehmensberatung tätig. Seine Schwerpunkte liegen besonders in den Bereichen Business Analyse, Projektmanagement und Qualitätssicherung.
 Alena Drebezgova studiert Wirtschaftsinformatik an der Universität Münster und arbeitet seit 2021 als Werkstudentin bei der viadee IT-Unternehmensberatung. Ihr Fokus liegt hierbei in den Bereichen Testmanagement und Qualitätssicherung.
Alena Drebezgova studiert Wirtschaftsinformatik an der Universität Münster und arbeitet seit 2021 als Werkstudentin bei der viadee IT-Unternehmensberatung. Ihr Fokus liegt hierbei in den Bereichen Testmanagement und Qualitätssicherung.
0 Kommentare